We made the Shadow Reader even faster – and friendlier to search engines!
We created the Shadow Reader to demonstrate how AMP pages can be used within a Progressive Web App (PWA) (read our announcement post for more context). The site repurposes existing articles from The Guardian into an immersive news reader experience. More than just a demo, it’s intended to be a fully functional site. It contains the end-to-end code needed to effectively combine AMP and PWA… it’s ready for production!
SEO for JS-generated content
As in any self-respecting single page application, the Shadow Reader’s initial HTML payload is small. It’s a thin app shell that loads quickly, giving the user something to look at while JavaScript loads the main content. This approach makes for a fine user experience!
Unfortunately, it can also present a challenge to search engines. Google will try to execute JavaScript in order to index what ultimately appears to the user, not just the initial HTML. But many search engines don’t or do so unreliably. In other words, it’s not safe to depend on a search engine to successfully execute your JavaScript. And if a search engine sees only the app shell, minus most or all of the content, it won’t be able to properly index the page.
Wouldn’t it be nice if the Shadow Reader’s article pages were served to search engines with text included right in the HTML? And wouldn’t it be amazing if that process didn’t slow down rendering, but instead gave us a way to serve those pages to new users in less than a second?
Turns out we can do both of those by serving the AMP version of articles to new users! After all, a web crawler appears to a server as a new user, too. So… how did we do it?
AMP⇒PWA
We did this by implementing an AMP⇒PWA pattern. Here’s how it works!
For a new user:
- When a new user visits an article page, we serve the AMP version of the article.
- The AMP uses <amp-install-serviceworker> to load and install the service worker.
- The service worker loads and caches the app shell.
- On the next page navigation, the service worker is in control – and so it gently brings the user into the PWA on that next page.
For an existing user, we simply serve the PWA.
That’s how our site can treat new users and existing users differently at the same URL. For existing users, the service worker is installed. And, when the service worker sees an article URL, it serves its cached version of the PWA.
How does this play out in the Shadow Reader? Let’s say a user first visits this article page:
https://amp.cards/theguardian/us/amazing_article
Seeing an article URL, the server returns the AMP version of the article, but one that installs a service worker when the article is loaded. The service worker, using the Workbox library, contains this line:
workboxSW.router.registerNavigationRoute('index.html')
This means, whenever the user navigates to a new URL on this domain, the service worker sees that request, and instead of passing it along to the server, it simply serves its cached version of index.html. That’s our PWA.
So if the user next clicks on a link to
https://amp.cards/theguardian/us/another_article
the service worker serves the cached PWA HTML. But the URL is unchanged! So when the PWA looks at the URL to parse out what article is being requested, it sees the link the user requested, and it can load the proper article into the PWA.
Thereafter, any time the user requests a Shadow Reader link, the service worker is already installed, and it serves the cached PWA.
Since a web crawler won’t allow us to install a service worker, a web crawler always gets served the AMP article.
Here’s that flow in a lovely diagram:
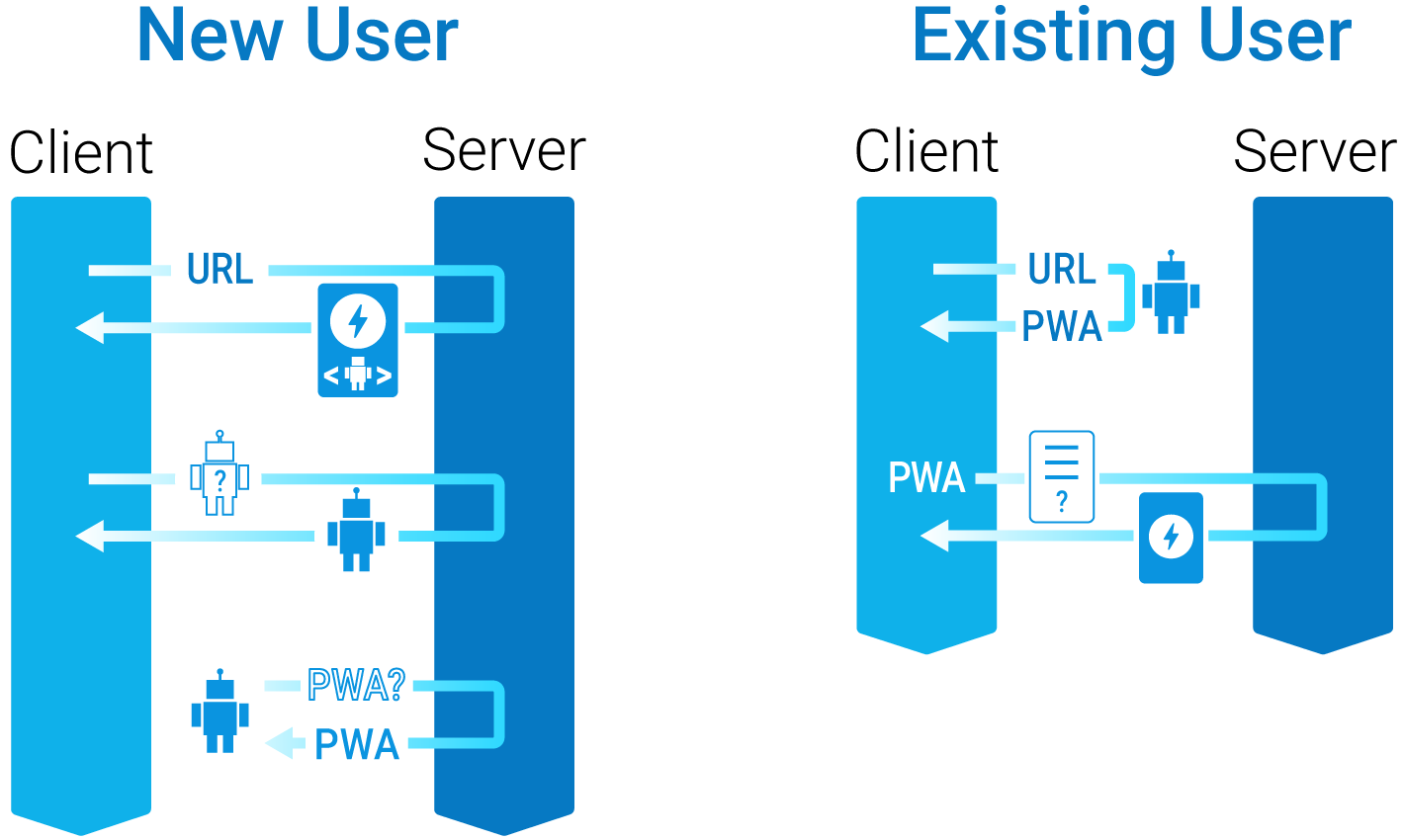

For a new user:
- The browser requests an article URL from the server. The server returns an AMP version of the article that includes <amp-install-serviceworker>.
- AMP’s serviceworker JS causes the browser to request the service worker. The server sends the service worker JS to the browser. The browser installs the service worker and starts it up.
- The service worker sends the server a request for the PWA app shell. The server sends those resources to the service worker, which caches them.
For an existing user:
- The browser sends a request for an article URL. This request is intercepted by the service worker. The service worker returns the cached PWA to the browser.
- The PWA requests the AMP article. This requests reaches the server, which returns the AMP article to the PWA. The PWA processes and displays that article.
Remember, a web crawler is always a new user!
What’s next?
Now that the Shadow Reader’s got its own server, we’ve got some new TODOs:
- In the future, we could forgo YQL altogether, simply using the Guardian’s RSS feed directly.
- We also should replace the Guardian’s top nav links with Shadow Reader links.
- We ask the AMP Cache to download and run the entire Shadow Reader in an iframe: <amp-install-serviceworker data-iframe-src=”https://amp.cards/index.html“>. It might be kinder to the casual user to specify a smaller page instead.
- Backend.js now gets used in the server as well as the front end, and the way we do that is a bit hacky. Perhaps we should refactor our code to use ECMAScript modules?
Please try this out, check out the code on github, and let us know what you think! We’re curious about how you’re trying out AMP/PWA patterns on your own site, and we’d love to get your ideas for Shadow Reader improvements.
Posted by Ben Morss, Developer Advocate, Google